Another way MPLS breaks traceroute
I recently got fiber to my house. Yay! So after getting hooked up I started measuring that everything looked sane and performant.
I encountered two issues. Normal people would not notice or be bothered by either of them. But I’m not normal people.
I’m still working on one of the issues (and may not be able to disclose the details anyway, as the root cause may be confidential), so today’s issue is traceroute.
In summary: A bad MPLS config can break traceroute outside of the MPLS network.
What’s wrong with this picture?
$ traceroute -q 1 seattle.gov
traceroute to seattle.gov (156.74.251.21), 30 hops max, 60 byte packets
1 192.168.x.x (192.168.x.x) 0.302 ms <-- my router
2 194.6.x.x.g.network (194.6.x.x) 3.347 ms
3 10.102.3.45 (10.102.3.45) 3.391 ms
4 10.102.2.29 (10.102.2.29) 2.841 ms
5 10.102.2.25 (10.102.2.25) 2.321 ms
6 10.102.1.0 (10.102.1.0) 3.454 ms
7 10.200.200.4 (10.200.200.4) 2.342 ms
8 be2878.ccr21.cle04.atlas.cogentco.com (154.54.26.129) 78.086 ms
9 be2717.ccr41.ord01.atlas.cogentco.com (154.54.6.221) 137.346 ms
10 be2831.ccr21.mci01.atlas.cogentco.com (154.54.42.165) 97.062 ms
11 be3036.ccr22.den01.atlas.cogentco.com (154.54.31.89) 108.071 ms
12 be3037.ccr21.slc01.atlas.cogentco.com (154.54.41.145) 118.264 ms
13 be3284.ccr22.sea02.atlas.cogentco.com (154.54.44.73) 137.982 ms
14 be2895.rcr21.sea03.atlas.cogentco.com (154.54.83.170) 139.721 ms
15 te0-0-2-3.nr11.b022860-0.sea03.atlas.cogentco.com (154.24.22.134) 139.110 ms
16 38.122.90.122 (38.122.90.122) 139.571 ms^C
I mean besides my ISP running infrastructure on RFC1918 addresses.
The problem is between hop 7 and 8. I just don’t believe it. There’s no way my ISP has a connection to a router 78ms away. cle04, that sounds like the airport code for Cleveland, Ohio. In any case it’s clearly in the US, and my ISP is not transatlantic.
Clearly there are missing router hops. This traceroute is a lie.
Here’s another lying traceroute:
$ sudo tcptraceroute -q 1 netnod.se
Running:
traceroute -T -O info -q 1 netnod.se
traceroute to netnod.se (192.71.80.67), 30 hops max, 60 byte packets
[…]
3 10.102.3.45 (10.102.3.45) 9.998 ms
4 10.102.2.29 (10.102.2.29) 9.981 ms
5 10.102.2.25 (10.102.2.25) 9.968 ms
6 10.102.1.0 (10.102.1.0) 6.423 ms
7 10.200.200.4 (10.200.200.4) 6.029 ms
8 et48.ro1-stb.netnod.se (81.19.110.46) 40.572 ms
9 www.netnod.fi (192.71.80.67) <syn,ack> 148.590 ms
No way my ISP peers with Netnod in Sweden directly. Not a chance.
And to get confirmation on that, let’s see who 81.19.110.46 actually is.
$ whois 81.19.110.46
[…]
role: NTT America IP Addressing
address: 8005 S Chester ST
address: Suite 200
address: Englewood, CO 80112
address: United States
phone: +1 303 645-1900
remarks: Abuse/UCE: abuse@ntt.net
remarks: Network: noc@ntt.net
remarks: Security issues: security@ntt.net
NTT. That’s way more plausible. NTT is a huge network provider, and I fully believe that my ISP would use them as transit to get to Sweden.
So clearly the packets are going from me, to my ISP, then to NTT, and then to Netnod.
But why am I not seeing the router hops inside NTT?
Brief summary of traceroute
If memory serves then traceroute was not designed into the internet protocols, but more like discovered.
You simply send a packet to the destination, but with a hop limit (poorly named “Time” to live, TTL. It’s not time, it’s hops) set to one. If the destination is more than one hop away, then you’ll get an ICMP TTL Exceeded message back, send by the last router you managed to get to. And then you send another packet with TTL set to 2, and repeat until you get a response from the destination itself.
More info in RFC1393. That traceroute IP option never really happened.
So why would hops be missing?
Sometimes you don’t get an ICMP TTL Exceeded. Often because the it was filtered, but it could also be because routers don’t have much CPU (compared to how much they can route “in hardware”), and may use control plane policing to limit the number of administrative packets like this that the router sends.
But those don’t manifest as a suspicious set of missing hops. They
show up as hops with an address of * in the traceroute.
In other words traceroute knows that nobody at all responded when it
sent with TTL=5, so on line 5 there will always be a result.
So that’s not it.
TTL modification
The only way a hop can be missing is if a router on the path increases the TTL of a packet.
This should never happen. (famous last words)
You can do this in Linux. For example with:
iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-set 64
But, uh, don’t do that at home. If you get a routing loop you could create imortal packets zooming around taking network bandwidth and CPU forever, possibly crashing all your routers and poisoning your cat.
Is my ISP doing this? Maybe. It’s not my primary guess, though. Mostly because it’s actually hard to do accidentally, and too dangerous to do on purpose.
MPLS
Let me explain! No, there is too much. Let me sum up.
MPLS encapsulates IP, sends it over the MPLS network, and then decapsulates it in order to send it back out on the other side.
Traceroute by default works fine through an MPLS network, because:
-
On encapsulation it copies the TTL from the IP packet into the MPLS TTL field.
-
For every hop in the MPLS network it decrements the MPLS TTL, but these hops do not look at the encapsulated IP TTL at all.
-
On decapsulation it takes the remaining MPLS TTL and uses it to overwrite the IP TTL, and sends the IP packet on its way.
So the net effect is that the TTL is decremented as if there were no tunneling.
An example TTL of a packet as it goes hop by hop may be:
5 4 3(ip=4) 2(ip=4) 1
A raw number here means IP TTL, and 3(ip=4) means an MPLS packet
with TTL 3, encapsulating an IP packet with TTL 4.
MPLS with network hiding
Ugh, I hate this feature so much. Please never use this feature.
You need to understand network hiding to see what the actual problem is, but I want to stress that it is NOT the case that NTT uses network hiding.
It sounds like it would be, but it’s not.
Network hiding changes the way MPLS encap and decap works with regards to TTL. With network hiding the behaviour changes to this:
-
On encap it ignores the IP TTL, and instead uses a high value (like 255) for MPLS TTL.
-
MPLS hops decrement this MPLS TTL value as normal.
-
On decap it sends the IP packet out AS-IS, without changing the TTL.
This means that it’s impossible for users outside the MPLS network to cause the TTL to expire inside the MPLS network. Therefore those hops will never send an ICMP TTL Exceeded, and there will be a suspicious “long hop” in the traceroute, covering the entire MPLS part. Kind of what I’m seeing.
An example TTL of a packet is now:
5 4 255(ip=4) 254(ip=4) 253(ip=4) 3 2 1
The TTL inside the MPLS network is no longer controlled by traceroute.
But that’s not it!
I have done many traceroutes. Some go via NTT. Some are direct peerings with my ISP. And they all show this weird gap. And I know for a fact that some of these networks do NOT use network hiding. In fact some don’t even use MPLS!
The only common factor here is my ISP.
Could it be that my ISP has a firewall rule that bumps up the TTL, before it leaves their network?
Theoretically yes, but… why? And how? This is a dangerous feature, and I would not expect normal routers to even have support for this.
An alternative theory: Misconfiguration
So how do you increase the TTL without increasing the TTL?
For network hiding you need to configure both the encap router and the decap router (ingress and egress) to use the other behaviour.
What if you configure only one side?
In this case it looks like my ISP only did this on the egress side. This means that:
-
On encap the IP TTL is copied to the MPLS TTL, and forwarded.
-
MPLS hops decrement the MPLS TTL. Hops inside my ISP still show up because my traceroute controls the TTL.
-
On decap the remaining MPLS TTL is thrown away, and the original IP TTL from encap is reused!
This means that for as many MPLS hops as we took inside my ISP, counting down the MPLS TTL, we will count them down AGAIN, before TTL expires.
Because of my ISPs configuration there’s no way to have the TTL expire for a few hops AFTER my ISP!
The TTL life is now:
5 4 3(ip=4) 2(ip=4) 1(ip=4) 3 2 1
You cannot set the TTL so that it expires right after the MPLS network. It either expires inside it, or it needs to count down again for a few hops..
And in the Netnod example above it removes all but the last NTT hop.
Can I reproduce this configuration error?
GNS3 is an amazing tool for this. It may not be able to simulate state of the art routers, but we don’t need to simulate 400Gbps links. A Cisco 7200 can do most things, including MPLS. Certainly enough for this experiment.
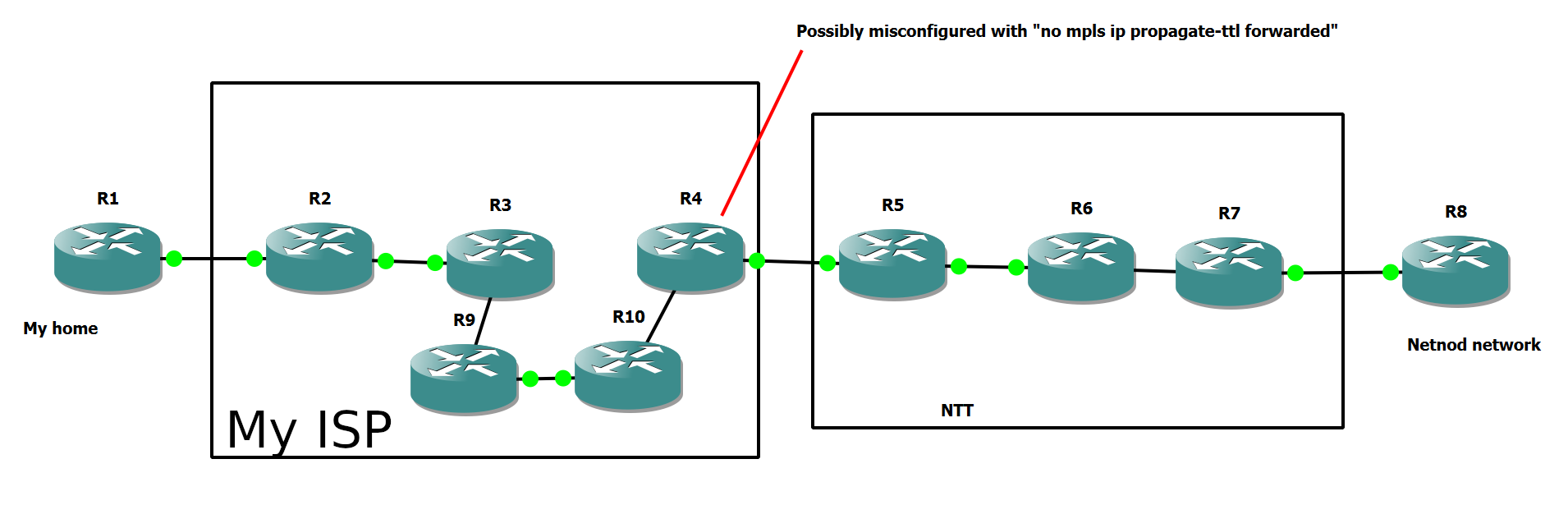
The IP address plan in the setup is, in short, that the last octet is the index of the router. So R6 has addresses of the form x.x.x.6.
Traceroutes in both directions when correctly configured:
R1#trace 8.8.8.8 so lo0
Type escape sequence to abort.
Tracing the route to 8.8.8.8
VRF info: (vrf in name/id, vrf out name/id)
1 12.0.0.2 8 msec 20 msec 12 msec
2 20.0.23.3 [MPLS: Labels 18/21 Exp 0] 88 msec 124 msec 124 msec
3 20.0.39.9 [MPLS: Labels 22/21 Exp 0] 92 msec 132 msec 120 msec
4 20.0.90.10 [MPLS: Labels 16/21 Exp 0] 116 msec 84 msec 84 msec
5 20.0.40.4 [MPLS: Label 21 Exp 0] 84 msec 76 msec 84 msec
6 23.0.0.5 80 msec 92 msec 92 msec
7 30.0.56.6 [MPLS: Labels 17/16 Exp 0] 176 msec 184 msec 188 msec
8 30.0.67.7 [MPLS: Label 16 Exp 0] 144 msec 164 msec 140 msec
9 34.0.0.8 192 msec 176 msec 172 msec
(the double MPLS labels are there because I used send-label on the
iBGP sessions in order to maximize the MPLS on the wire otherwise lost
to penultimate hop popping. You don’t need to know what any of that
means)
R8#traceroute 1.1.1.1 so lo0
Type escape sequence to abort.
Tracing the route to 1.1.1.1
VRF info: (vrf in name/id, vrf out name/id)
1 34.0.0.7 12 msec 16 msec 16 msec
2 30.0.67.6 [MPLS: Labels 16/25 Exp 0] 80 msec 80 msec 48 msec
3 30.0.56.5 [MPLS: Label 25 Exp 0] 60 msec 48 msec 44 msec
4 23.0.0.4 40 msec 52 msec 104 msec
5 20.0.40.10 [MPLS: Label 23 Exp 0] 144 msec 184 msec 180 msec
6 20.0.90.9 [MPLS: Label 20 Exp 0] 176 msec 180 msec 164 msec
7 20.0.39.3 [MPLS: Label 17 Exp 0] 188 msec 184 msec 180 msec
8 20.0.23.2 [MPLS: Label 16 Exp 0] 148 msec 120 msec 152 msec
9 12.0.0.1 140 msec 164 msec 148 msec
But changing just one thing, adding no mpls ip propagate-ttl forward
to R4 (in my ISP), suddenly all of NTT (not my ISP!) disappears
from the traceroute:
R1#trace 8.8.8.8 so lo0
Type escape sequence to abort.
Tracing the route to 8.8.8.8
VRF info: (vrf in name/id, vrf out name/id)
1 12.0.0.2 12 msec 20 msec 16 msec
2 20.0.23.3 [MPLS: Labels 18/21 Exp 0] 84 msec 132 msec 112 msec
3 20.0.39.9 [MPLS: Labels 22/21 Exp 0] 124 msec 92 msec 104 msec
4 20.0.90.10 [MPLS: Labels 16/21 Exp 0] 128 msec 120 msec 92 msec
5 20.0.40.4 [MPLS: Label 21 Exp 0] 96 msec 96 msec 104 msec
6 34.0.0.8 168 msec 140 msec 168 msec
Traceroute in the other direction when propagate-ttl is disabled on R4 makes NTT perfectly visible, but hides some of my ISP, as expected:
R8#traceroute 1.1.1.1 so lo0
Type escape sequence to abort.
Tracing the route to 1.1.1.1
VRF info: (vrf in name/id, vrf out name/id)
1 34.0.0.7 16 msec 8 msec 8 msec
2 30.0.67.6 [MPLS: Labels 16/25 Exp 0] 40 msec 60 msec 40 msec
3 30.0.56.5 [MPLS: Label 25 Exp 0] 60 msec 48 msec 56 msec
4 23.0.0.4 80 msec 72 msec 80 msec
5 20.0.23.2 [MPLS: Label 16 Exp 0] 148 msec 160 msec 164 msec
6 12.0.0.1 144 msec 168 msec 144 msec
So this experiment confirms that the theory explains what I’m seeing.
Side track: What if only encap has this setting?
The quick reader may wonder if only the ingress router has TTL propagation off then perhaps TTL will get bumped from 4 or so all the way up to 250+. That is, like so:
5 4 255(ip=4) 254(ip=4) 253(ip=4) 252 251
That would make sense, per my description above about decap. It’s supposed to take the MPLS TTL and overwrite the IP TTL.
But no, it does not.
This makes sense to me, and is the obviously correct way for a router that does TTL propagation to behave. To never overwrite the IP TTL with a higher value.
This is because if the decap router propagates TTL, then it should assume that the encap router did too. And if the encap router does, then the MPLS TTL will always be lower than the IP TTL.
If it sees an MPLS TTL greater than IP TTL, then it knows that there is a mismatch, and it does the safe thing to avoid imortal packets and router crashes / network collapse.
This “do the right thing” can only be done when TTL propagation is turned on (the default). When turned off there’s no way for the router to know which TTL is correct, so it has to use the IP TTL in all cases.
So is that what my ISP is doing?
Maybe. It fits. I’m emailed their support, and am awaiting a reply.
I swear life would be so much easier for everyone involved if any ISP I get would just give me admin access to their network.
Of course the first thing I’d do would be to set up IPv6…