Fast zero copy static web server with KTLS
I’m writing a webserver optimized for serving a static site with as high performance as possible. Counting every syscall, and every copy between userspace and kernel space.
It’s called “tarweb”, because it serves a website entirely from a tar file.
I’m optimizing for latency of requests, throughput of the server, and scalability over number of active connections.
I won’t go so far as to implement a user space network driver to bypass the kernel, because I want to be able to just run it in normal setups, even as non-root.
I’m not even close to done, and the code is a mess, but here are some thoughts for now.
First optimize syscall count
Every syscall costs performance, so we want to minimize those.
The minimum set of syscalls for a webserver handling a request is:
accept()to acquire the new connection.epoll_ctl()to add the fd.epoll_wait()&read()or similar. (ideally getting the whole request in oneread()call)epoll_wait()&write()or similar. (again ideally in one call)close()the connection.
There’s not much to do about accept() and read(), as far as I can
see. You need to accept the connection, and you need to read the data.
Reading the request
You could try to wait a bit before calling read(), hoping that you
can coalence the entire request into one read() call. But that adds
latency to the request.
You could call getsockopt(fd, SOL_TCP, TCP_INFO, …) and use
tcpi_rtt to try to estimate how long to wait, but it depends on too
many factors so it’s likely to add latency no matter what you do.
It would also add another syscall, which is what we wanted to avoid in the first place.
It’s probably best to read data as soon as it’s received. That way you can start parsing headers even though the whole request has not been received. When the request is fully received you’re already ready to send the reply.
There’s also nothing to be done about copying data from kernel space
to userspace on read(). Short of implementing the webserver in the
kernel (possibly using BPF) or a user space network stack, there’s
nothing you can do.
If you use nonblocking sockets you can try a read() right after
accept(), in case the client has already landed some data. That
saves a syscall if correct, and wastes a syscall if incorrect.
Writing the reply
First I implemented memory mapping the file, and using a single
writev() call to write both headers and file content in one syscall.
For minimizing number of syscalls this is great. It also has the benefit of being perfectly portable POSIX. For copying data between kernel and user space it’s not so great, though.
So then I implemented sendfile(). It does mean one more syscall (one
writev() for the headers, one for the contents), but removes the
data copies for the content.
I will add preprocessing of the tar file so that I’ll be able to
sendfile() headers and content in one go. That won’t work for Range
requests, but most requests are not Range requests.
Compression
It’s simple enough to pre-compress files. So that if a client says
that it accepts gzip, you can just serve index.html.gz instead of
index.html.
TLS
At first I only targeted HTTP, because surely TLS would always make things slow? Felt a bit anachronistic though. Maybe just place a proxy in front, to do TLS? But that will reduce performance, which is the whole point.
But then I read up more on KTLS. It lets you do the handshake in user space, but then hand off the session and symmetric encryption to the kernel. The socket file descriptor transparently becomes encrypted.
This allows me to use the same writev() and sendfile()
optimizations after the TLS handshake. If network hardware allows,
this can even offload TLS to the network card. I don’t have such
hardware, though.
OpenSSL supports KTLS, but as of today not for TLS 1.3 on the read
path. So I had to hardcode using TLS 1.2. Alternatively I could use
SSL_read() for the read path, and plain sendfile() on the write
path.
So what’s the performance?
There are two ways to measure that. One is how fast you can go on high end hardware. But for something like this you’ll need really fancy stuff, and dedicated machines. And that’s just for the server itself. You’ll also need beefy load generators.
And network gear capable of hundreds of Gbps.
The other is to go with low end hardware, so you can easily saturate it.
I went with the latter. Specifically a Raspberry Pi 4.
The downside to the Raspberry pi in this regard is that on HTTP it’s not hard to completely saturate the 1Gbps network interface, and with HTTPS it doesn’t have AESNI, so the results don’t scale up to what someone would actually run on a real server.
An alternative is to compare resource usage per request. E.g. how much
CPU does writev() use compared to sendfile() for HTTP? And then we
can compare that to HTTPS.
When we look at how much CPU time is used we don’t even have to put the system under 100% load.
writev() vs writev()+sendfile()
writev() can write headers and content in one syscall. sendfile()
requires two. One for the headers and one for writev(). So
writev() should be faster for small files, and sendfile() faster
for large files.
Looks like the cutoff point is a couple of MB. But the signal is noisy.
I ran 100 requests at every MB from 1 to 100. Then 1000 requests between 0 and 10MB at every 20kB.
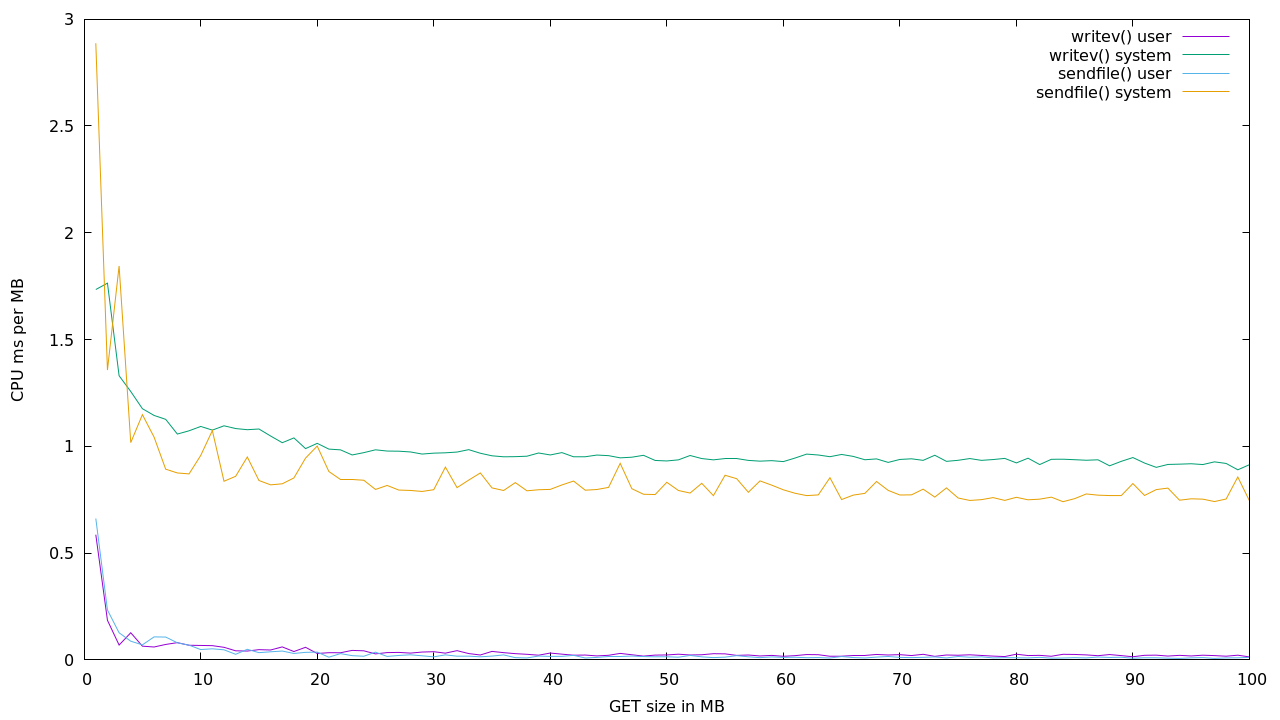
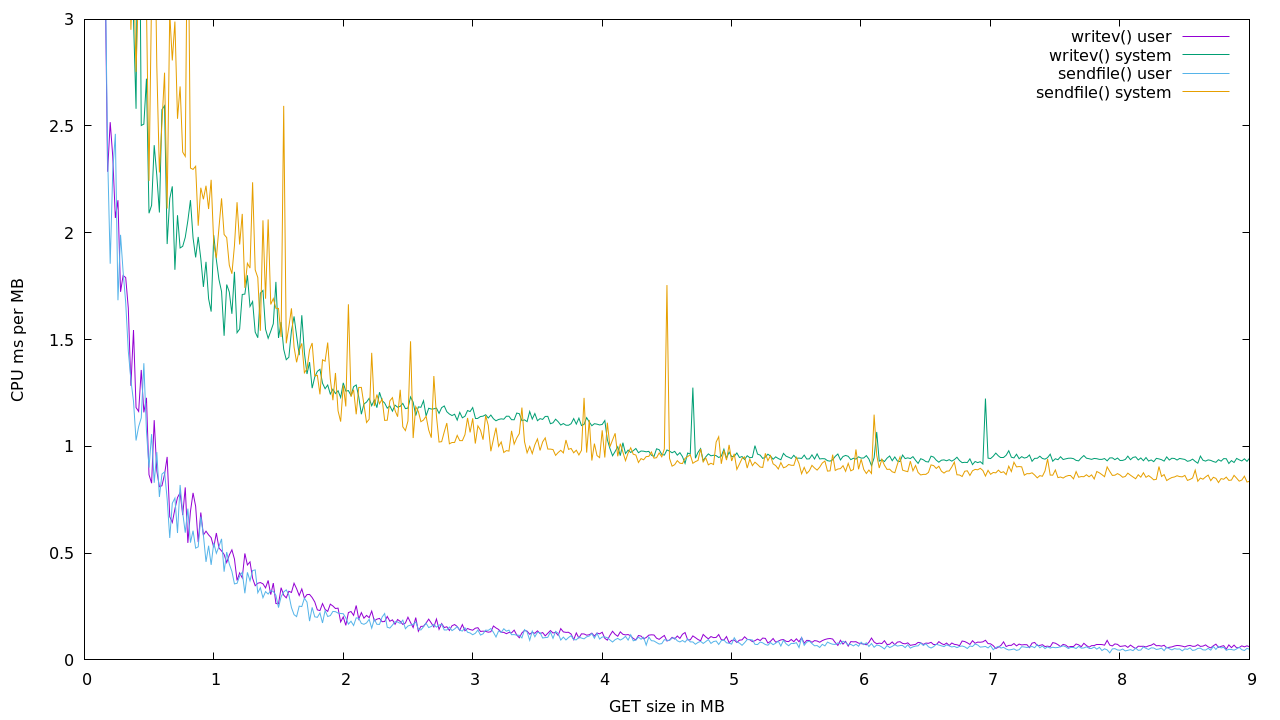
Note that CPU use isn’t everything. At higher speeds you should expect
the memory bandwidth to be the bottleneck. sendfile() may be a small
gain in CPU, but should be a bigger deal for shuffling bytes across
buses.
Supposedly a Raspberry Pi has over 4 GBps memory bandwidth, so about 32x what the built in wire network interface can push out.
Future work
Benchmark KTLS vs normal TLS vs HTTP
I would’ve done this, but the default Raspberry Pi kernel doesn’t include KTLS. This is the second time I’ve found it underconfigured. It also doesn’t include nftables bridge support.
Bleh, why not just include everything reasonable?
Optimize and benchmark for NUMA
This requires beefier machines, but I guess the idea is to do Netflix style and route requests to the node where the data is.
That, or let network routing take care of it, and give each node a complete copy of the data. Netflix doesn’t do this because they don’t want to waste IPv4 addresses, but for this pet project I don’t have to care about IPv4.
Graph performance of concurrent requests
Probably I’d need some tweaking to fix some inefficiencies in my use of epoll. And increase the socket limits.
Tangent: Benchmarking over loopback
To my surprise just using writev() was about twice as fast as using
writev()+sendfile() when testing locally, for large files. And
slightly faster even with small files.
But then I saw that over loopback (127.0.0.1) the writev() (and
sendfile()) will have no problems sending a whole GB in one
call. Basically there’s a kernel shortcut somewhere for localhost
communication.
writev(7, [{iov_base="HTTP/1.1 200 OK\r\n", iov_len=17}, {iov_base="Content-Length: 1000000000\r\n\r\n", iov_len=30}, {iov_base="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., iov_len=1000000000}], 3) = 1000000047
So always benchmark over an actual network, to get useful results.
Tangent: building on a Pi
In order to get a compiler with more modern C++ I had to build from source. Not exactly a quick thing to do. Over 14 and a half hours on a Raspberry Pi 4.
real 878m54.181s
user 778m17.517s
sys 32m56.963s
I built in without concurrency because I’ve made the mistake before of running out of RAM building GCC before, and it’s not a happy story.
Links
- NUMA Optimizations in the FreeBSD Network Stack
- FreeBSD optimizations used by Netflix serving at 800Gb/s
- Found much later: Intel also found that
sendfile()is only faster for larger files. See slide 12 of this presentation. Though their breakeven seems to be 16kB, in slide 11.